Introduction
What is AL, ML, DL?
In a broad sense Artificial Intelligence (AI) is a concept that refers to machines that approximate human reasoning while performing complex tasks. One goal of AI is to augment human intelligence via enhanced pattern recognition, especially for tedious tasks. Machine Learning (ML) refers to a set of models within the AI framework that can learn without hard-coded rules. For example, regression and classification trees can effectively quantify non-linear relationships between variables with relatively little data to predict species spatial distributions. Further, Deep Learning (DL) is a sub-set of ML models that consist of neural network approaches with the ability to adapt and learn from datasets that, in some applications, can be exceptionally large and beyond the capabilities of conventional computer hardware.

While ML models are effective at reducing the analytical load for human researchers, some ML models require carefully curated training data to produce accurate results. Training data may need to be specific to regions or periods of time, as differences in background conditions, soundscapes, and animal behaviors can affect the accuracy of object identification and pattern recognition. Finally, the vast potential of ML for environmental data has led to a huge number of researchers independently building ML models with significant duplication of effort. Increased cooperation among environmental ML users and stakeholders will lead to increased efficiency and decreased costs.
Pipeline Components
Every ML application consists of three components: the Data, the Model, and the Deployment. It is possible to piece together a series of open-source tools to process each step, but it is more common to find an end-to-end solution that completes all of these steps together under a “platform as a service” license agreement.
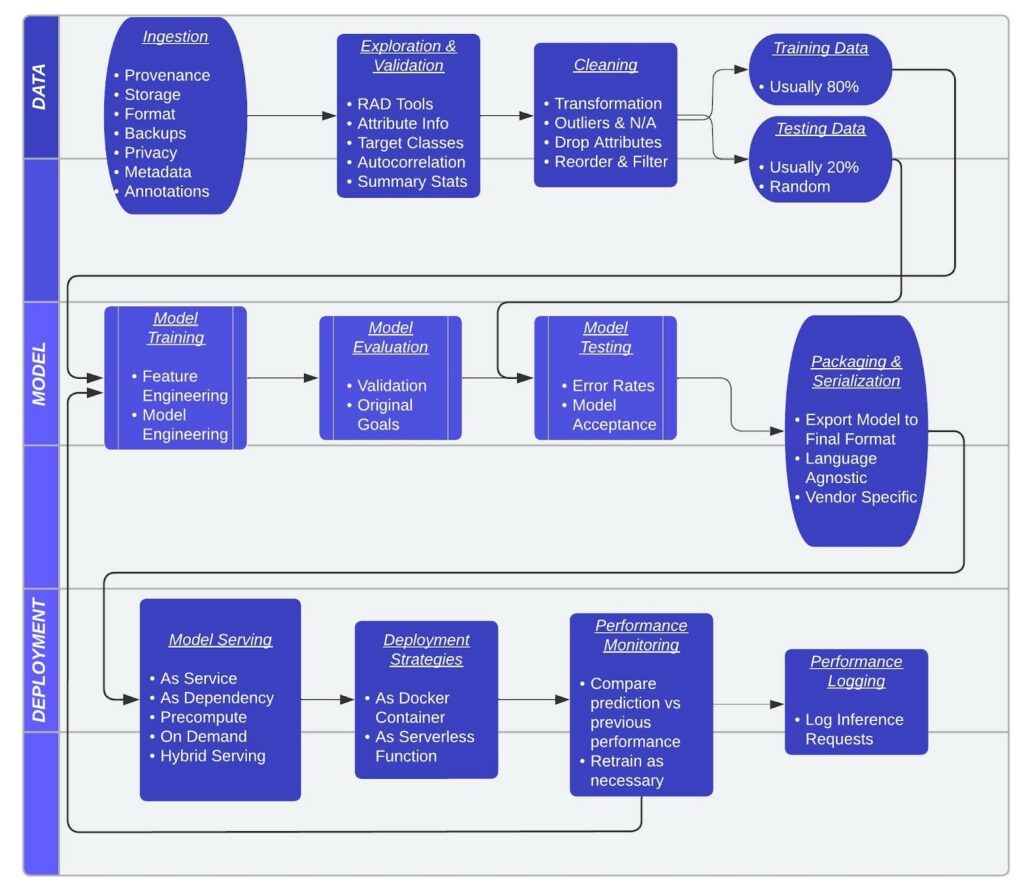
Generalized pipeline steps and considerations for developing ML models. Adapted from “INNOQ” under Creative Commons Attribution 4.0 International Public License.
A ML framework is any tool or library that allows users to create a ML model without requiring specialized knowledge about the underlying algorithm. A ML platform uses a ML framework(s) as the basis for a pipeline development environment. A platform may focus on one component of a pipeline (i.e., data processing, model development, or deployment), or all of the components. Further, different model components can be stored in a feature store, or a data management tool containing information on the model variables, inputs, and attributes to make it easier to share and deploy a model.
Several major cloud-based technology companies (i.e., Microsoft, Google, Amazon) offer a ML platform that provides streamlined end-to-end solutions with approachable low-code or pre-defined environments. These services can develop the entire pipeline with little coding, or alternatively, provide a single step in a custom pipeline (e.g., access to data via cloud-storage).
End-to-end solutions are designed to call other open-source tools for individual steps within a pipeline as mico-services to record the AI workflow being used and to enable reproducibility. Of these platforms, Google AI seems to be the most approachable because users only need a Google account to start; and users have access to extensive tutorials and documentation with transparent pricing for additional services (e.g., storage, processing).
ML Platform Examples
Platform name, launch date, use, low-code, and feature store information (Hellström 2021).
| Name (Launch) | Use | Low-Code | Feature Store |
| Adlik (2020) | Deployment | No | No |
| Algorithmia (2014) | Deployment | No | No |
| Altair Knowledge Studio (2014) | End-to-End | Yes | No |
| Alteryx (2020) | End-to-End | No | No |
| Anaconda Enterprise (2020) | End-to-End | No | No |
| Arrikto Enterprise Kubeflow (2019) | End-to-End | No | No |
| Auger (2019) | Development | No | No |
| AWS SageMaker (2017) | End-to-End | No | Yes |
| Azure ML (2019) | End-to-End | No | No |
| Basis AI Bedrock (2018) | End-to-End | No | No |
| BentoML (2019) | Deployment | No | No |
| BigML (2015) | End-to-End | No | No |
| C3.AI (2009) | End-to-End | Yes | No |
| Canonical Charmed Kubeflow (2019) | End-to-End | No | No |
| Cloudera ML (2019) | End-to-End | No | No |
| cnvrg.io (2016) | End-to-End | No | No |
| Comet (2017) | Development | No | No |
| Cortex (2019) | Deployment | No | No |
| Cubonacci (2018) | End-to-End | No | No |
| D2iQ Kaptain (2020) | End-to-End | No | No |
| Databricks Data Science Workspace (2013) | End-to-End | No | Yes |
| Dataiku (2013) | End-to-End | No | No |
| DataRobot (2012) | Development | Yes | No |
| Dataspine (2017) | End-to-End | No | No |
| Datatron (2016) | Deployment | No | No |
| Determined AI (2020) | End-to-End | No | No |
| Digazu (2018) | End-to-End | No | No |
| Domino Data Lab (2013) | End-to-End | No | No |
| dotData Enterprise (2018) | End-to-End | Yes | No |
| Explorium Data Science Platform (2017) | End-to-End | No | No |
| Faculty (2014) | Deployment | No | No |
| FloydHub (2016) | Development | No | No |
| Flyte (2019) | End-to-End | No | No |
| ForePaaS (2019) | End-to-End | Yes | No |
| GCP Vertex AI (2019) | End-to-End | No | Yes |
| Grid Dynamics (2010) | End-to-End | No | No |
| H2O Driverless AI (2012) | End-to-End | No | No |
| HPE Ezmeral MLOps (2020) | End-to-End | No | No |
| Hypergiant (2018) | End-to-End | No | No |
| IBM Watson ML (2014) | End-to-End | No | No |
| Iguazio (2014) | End-to-End | No | Yes |
| KNIME (2008) | End-to-End | Yes | No |
| Kubeflow (2018) | End-to-End | No | Yes |
| Logical Clocks Hopsworks (2016) | End-to-End | No | Yes |
| Ludwig (2019) | Development | Yes | No |
| MathWorks ML toolboxes (2004) | End-to-End | No | No |
| Merlin (2020) | Deployment | No | No |
| Metaflow (2019) | End-to-End | No | No |
| MLeap (2016) | Deployment | No | No |
| Neptune (2017) | Development | No | No |
| NVIDIA Triton (2018) | End-to-End | No | No |
| One Convergence DKube (2018) | End-to-End | No | No |
| Onepanel (2020) | Development | No | No |
| Pachyderm (2014) | End-to-End | No | No |
| Paperspace Gradient (2014) | End-to-End | No | No |
| Peltarion (2005) | End-to-End | Yes | No |
| PI.EXCHANGE (2019) | End-to-End | No | No |
| Polyaxon (2018) | Development | No | No |
| RapidMiner (2007) | End-to-End | Yes | No |
| RAPIDS (2018) | Development | No | No |
| Red Hat Open Data Hub (2019) | End-to-End | No | No |
| RocketML (2017) | End-to-End | No | No |
| Run:AI (2018) | Development | No | No |
| SAP ML Lab (2020) | End-to-End | No | No |
| SAS Visual Data Mining and Machine Learning (2016) | Development | No | No |
| Seldon Core (2018) | Deployment | No | No |
| Snorkel (2016) | End-to-End | No | No |
| Spell (2017) | End-to-End | No | No |
| Splice Machine ML Manager (2012) | End-to-End | No | Yes |
| Stradigi Kepler (2004) | End-to-End | Yes | No |
| Submarine (2020) | Development | No | No |
| TFX (2019) | End-to-End | No | No |
| TIBCO Data Science (2018) | End-to-End | No | No |
| Valohai MLOps Platform (2016) | End-to-End | No | No |
| Verta (2018) | End-to-End | No | No |
ML Framework Examples
| Name | Information Source |
| Apache MXNet | Amazon Sagemaker Documentation |
| Apache Spark | Amazon Sagemaker Documentation |
| Caffe Berkeley AI | NIST |
| CatBoost | BentoML |
| Chainer | Amazon Sagemaker Documentation |
| Detectron2 | BentoML Documentation |
| EasyOCR | BentoML Documentation |
| H2O | BentoML Documentation |
| Hugging Face | Amazon Sagemaker Documentation |
| Keras | BentoML Documentation |
| LightGBM | BentoML Documentation |
| Machine Learning in R (mlr) | NIST Documentation |
| MLFlow | BentoML Documentation |
| MXNet Gluon | BentoML Documentation |
| ONNX | BentoML Documentation |
| ONNX-mlir | BentoML Documentation |
| PaddlePaddle | BentoML Documentation |
| Picklable Model | BentoML Documentation |
| PyCaret | BentoML Documentation |
| PyTorch | BentoML Documentation |
| PyTorch Lightning | BentoML Documentation |
| Ray RLLib | Azure Machine Learning Documentation |
| Scikit-Learn | BentoML Documentation |
| SpaCy | BentoML Documentation |
| SparkML Serving | Amazon Sagemaker Documentation |
| Statsmodels | BentoML Documentation |
| Tensorflow | BentoML Documentation |
| Tensorflow V1 | BentoML Documentation |
| Torch | NIST Documentation |
| Transformers | BentoML Documentation |
| Triton Inference Server | Amazon Sagemaker Documentation |
| XGBoost | BentoML Documentation |
Costs
In an example, we compared the costs of manually categorizing fish species and behaviors versus producing an automated AI pipeline via contracting with a private vendor in an underwater video use case. The goal of this study was to identify the non-consumptive effects of predator occurrence on reef fish grazing behavior in the Florida Keys. At the time, research scientists and volunteers manually recorded 21 predator (e.g., barracuda) and herbivore (e.g., parrotfish) species observations from 550 hours of underwater video. When examined manually, 51 volunteers processed 550 video hours over 1.5 years with the total price limited to storing approximately 3 TB of data (< $1,000).
We were advised that commercial rates for producing an AI pipeline to automatically detect 21 fish species required 250 annotations per species and behavior to train an object detection model for 100 hours of labor, assuming annotated data already exist. Many companies offer manual annotation as a service based on, for example, the number of bounding boxes and the number of human labelers. At Google, an image with 3 bounding boxes and 2 labelers would count as 6 units (3 x 2) and annotation would be billed at $63 per 1,000 units in 2022. Therefore the cost for this project would entail 100 hours of contracting labor and 5,250 (21 species x 250 annotations) annotation units, or approximately $300 to $400 for one labeler via Google. Additionally, cloud-storage can be accessed at $0.02 per GB in 2022.
In this example, the time required to prepare video files, annotate, process data, and build a simple object detection model is significantly lower than manually processing data, and can be achieved at a reasonable financial cost. Additionally, while projects over long time periods can have high initial time commitment for annotation, the time commitment is reduced as future complementary datasets may require little to no additional annotation.
Costs: GPUs
ML pipelines use central processing units (CPUs) and graphics processing units (GPUs). CPUs are general units that process a computer’s basic sequential commands. GPUs render images, video, and animations by dividing complex tasks into smaller parts and running tasks in parallel to speed up operations; GPUs have since been applied to ML pipelines to speed up model training because GPUs can process large volumes of data more efficiently than CPUs.
Working on a CPU for ML tasks is preferable for working locally (i.e., not in a cloud environment) to provide real-time inference on model performance and for performing sequential model tasks. CPUs can be used to work with a pipeline to get it up and running on a smaller subset of data. Additionally, the cost is lower than working with a GPU because a CPU is native to a personal computer.
However, GPUs are the preferred option for model training in most ML pipelines because of their ability to process the volume of data necessary to train effective ML models. GPUs have evolved from working on personal computers to working in cloud environments, where GPUs can be rented as-needed for processing tasks. Amazon, Google, Microsoft, and many others provide access to GPU resources. Access is often through a virtual machine (VM) tied to GPU resources; VMs act as an intuitive desktop terminal that can be accessed through any computer, where modeling tasks can be set to run without keeping a local machine running. For example, you could sign up for a machine learning VM in Microsoft Azure to create an environment automatically populated with necessary libraries, select the GPU settings you need for the VM, and run your code within the environment with relative ease. GPU resources are scalable depending on RAM requirements and the number of GPUs required; prices range from $0.25 per hour to $5.00 per hour with some models taking several days to run (e.g., https://github.com/the-full-stack/website/blob/main/docs/cloud-gpus/cloud-gpus.csv).
Getting Started
A range of resources offer introductory material on data processing, model training and validation, and deployment (e.g., Google AI Tutorials, Roboflow Notebooks). In lieu of reproducing this information, which can emphasize computer science and statistical issues beyond scope, we provide a high level view of annotation, formatting, model types, storage, metadata standards, worked examples, and general best practices to help researchers prepare for an AI project and to navigate unfamiliar concepts that need to be considered before starting a project.
Common Concepts and Terms
- Structured vs. Unstructured Data
- Structured Data is organized in a defined format, such as rows and columns in a database.
- Unstructured Data is stored in a native format, such as individual photos, videos, or audio files.
- Image, Video, and Audio Data
- Classification: Identifies the presence of an object in single-label classification or multiple objects in multi-label classification
- Object Detection: Identifies the presence and location of an object or multiple objects
- Semantic Segmentation: Labeling every pixel or audio segment according to its classification
- Instance Segmentation: Labeling every pixel or audio segment according to its classification and separating different objects of the same class
- Action Identification: Detects dynamic action or movement
- Tabular Data
- Classification: Predicts an outcome from two classes in binary classification or three or more classes in multi-class classification
- Regression: Predicts an outcome from a continuous set of values
- Forecasting: Predicts a sequence of outcomes from time series data
Data Preparation
Imagery prep
ML models can analyze image data for single-label and multi-label classification, object detection, and instance segmentation. The basic requirements for image data for ML models focus on the format and size of the images regardless of objective. The required format changes depending on the pipeline used, but generally the accepted file formats include JPEG, GIF, PNG, BMP, and ICO. File sizes and resolutions also vary depending on the pipeline and may require storage in certain types of services. For example, Google’s Vertex AI image preparation workflow has a maximum individual file size of 30MB for training data but only 1.5MB for prediction data, with training images resized to 1024 * 1024 pixels. Smaller file sizes are also required by frameworks such as Apache MXNet, which utilizes a workflow where images are resized to 256 * 256 pixels and compressed into JPEG formats. Images used for training should be very similar to those for predictions. Some frameworks may require pre-processing images for coloration, such as centering RGB pixel values, across the dataset. Resolution, size, and conditions should be matched as closely as possible between the training and prediction data, and training data should have multiple angles and backgrounds to improve accuracy. Random cropping, mirroring, and changes in brightness, contrast, and color can be used to further enhance the library of training images. Advanced ML pipelines use “synthetic data” to automatically introduce randomness and alternative views into training and testing data.
Image Checklist:
- Sized uniformly according to framework requirements.
- Converted to format optimized for framework.
- Compressed and stored for optimal access by model.
- Match resolution and conditions between training and prediction data.
- Create additional training images by adjusting existing images.
Video prep
The application of ML to video data includes objects such as classification, action recognition, and object tracking. Standard ML models for classification and object tracking may analyze video by extracting frames as individual images (i.e., statically), which results in similar requirements for video as for image data. However, more sophisticated analyses consider the fact that sequential frames are correlated and related, which can be leveraged by ML models to further improve accuracy. Video data must be formatted appropriately for the framework or pipeline, and video files and image files from extracted frames must be sized correctly. In Google’s Vertex AI video analysis pipeline, videos must be less than 50 GB and 3 hours in length with correct timestamps. Video frame resolution will be reduced to 1024 * 1024 pixels. As with image data, training data from videos should match the resolution, size, and conditions in the prediction data.
Video Checklist:
- Sized uniformly according to framework requirements.
- Converted to format optimized for framework.
- Compressed and stored for optimal access by model.
- Match resolution and conditions between training and prediction data.
Acoustic prep
Like video data, acoustic data is analyzed by ML models using images, where sound is converted to spectrograms or waveforms. The objectives of ML pipelines for acoustic data are object detection and classification, where the objects of interest are specific sounds. As with image and video data, acoustic data need to follow the formatting and size requirements of ML frameworks used for analysis. This is critical when converting the raw audio files (e.g., WAV, MP4, WMA) into spectrograms or waveforms to ensure the resulting images are suitable for analysis. The length of the converted audio clips should be sufficient to contain the entire sound of interest while fitting within size requirements. Training data from audio clips should match the prediction data as closely as possible, and audio manipulation such as adjusting volume or adding background noise can be used to provide a wider range of training data.
Acoustic Checklist
- Format raw audio files for conversion to spectrograms or waveform.
- Format spectrograms or waveforms for ML framework.
- Size and compress spectrograms or waveforms.
- Match spectrographs or waveforms between training and predicted data.
Tabular prep
Tabular data can be analyzed by ML models with the outcomes of classification, forecasting, or regression. ML frameworks should be applied to “Big Data”; datasets so large and complex that traditional statistical techniques are too time-consuming and resource intensive. As such, ML models recommend having large amounts of training data. Google’s Vertex AI tabular data pipeline suggests classification models to have 50 rows times the number of features, regression models 200 times the number of features, and forecasting models 5000 times the number of features and at least 10 unique steps in the time series. Additionally, the training data should capture the variation present in the prediction data. There are many options for storing tabular data, including CSV files and database tables. However, using a non-optimized file format will limit the efficiency of ML models and greatly increase run times and costs. Instead, tabular data should be stored in formats that allow for ML frameworks to quickly and efficiently import observations. Vertex AI recommends using BigQuery tables for tabular data. However, the general recommendation for formatting tabular training data calls for the petastorm format, which has the most complete set of features and is natively supported by most common ML frameworks. In any format, tabular data needs to be cleaned prior for use as training data. Data should be labeled consistency and missing data should be minimized as much as possible. Highly correlated variables should be identified and reviewed to avoid statistical issues. Finally, the cleaned up tabular data should be explored to ensure that the dataset is suitable to achieve the objective via the chosen ML framework.
Tabular Data Checklist
- Format tabular data for optimal storage and intake by ML models.
- Store data recommended by ML framework.
- Fix labels for consistency and check missing values.
- Review correlated variables.
- Explore data to ensure suitability for objectives.
Annotation Tools
When classification and/or object detection are the goals of an AI project, there are two common approaches: image classification and object classification within images. Under image classification, the goal is to classify a whole image as containing or consisting of the object of interest. Alternatively, detecting objects within images requires a form of localization, or a means to identify and record where the object occurs in the image. Localization via rectangle is the most common approach, but point and polygons can also be used (example). Both video and acoustic data can also be used in object detection as well. Video data can be processed into individual frames (i.e., images) for object detection tasks, and acoustic data can be converted to spectrograms and waveforms for the same purpose.
A variety of image annotation tools are popular in the marine science community. Annotation tools help create annotated data in the form of small files that identify the object of interest in a whole image, or alternatively, an object of interest within an image with additional information on localization attributes (i.e., the pixel level coordinates of a bounding box). Annotation tools require a list of labels or categories used to describe each object of interest, called a labelset.
Google’s AI Platform provides some recommendations for developing a labelset:
- Labeling/annotating data is more effective and accurate when there are less than 20 categories/labels used to describe imagery because it is difficult for human labelers to track highly categorical data.
- Labels should be meaningful rather than abstract. For example, “Carcharodon carcharias” is more meaningful than “label1”.
- Labels should be easily distinguishable from other labels.
- Consider including a label named “other” or “none” for data that don’t match the other labels. Every image in the dataset must have a label from the labelset.
Members of the marine science community also maintain ongoing lists of annotation tools on GitHub, and slack channels for scientists working in marine AI. The tool list is reproduced here, with additions, for redundancy and future access under distribution provisions of Apache License 2.0:
Image Annotation Tools
| Name | Free | Open Source | Notes |
| BenthoBox | Yes | No | |
| BIIGLE | Yes | Yes | https://github.com/biigle/ |
| Coral Point Count with Excel extensions | Yes | No | |
| CoralNet | Yes | No | |
| cvat | Yes | Yes | |
| Deep Sea Spy | No | No | |
| Labelbox | No | No | |
| labelme | Yes | Yes | |
| OFOP | No | No | |
| RectLabel | No | No | |
| SeaGIS | No | No | Includes EventMeasure and TransectMeasure |
| Sebastes | Yes | Yes | |
| Squidle+ | Yes | Yes | Source Code |
| Supervisely | No | No | |
| Tator | Yes | Yes | See: Tutorials and Source Code |
| VIAME | Yes | Yes | All Docs |
| VoTT | Yes | Yes | |
| FishID | Yes | No | Send an email to fishidglow@outlook.com to access and collaborate |
Video Annotation Tools
| Name | Free | Open Source | Notes |
| ADELIE | Yes | No | |
| BIIGLE | Yes | Yes | https://github.com/biigle/ |
| Digital Fisher | No | No | |
| MBARI Media Management (M3/VARS) | Yes | Yes | Quickstart |
| Scalabel | Yes | Yes | |
| SeaTube | Yes | No | |
| Tator | Yes | Yes | See: Tutorials and Source Code |
| Video Annotation and Reference System (VARS) | Yes | Yes | |
| video-annotation-tool | Yes | Yes | |
| VIAME | Yes | Yes | All Docs |
| FishID | Yes | No | Send an email to fishidglow@outlook.com to access and collaborate |
Acoustic Annotation Tools
| Name | Free | Open Source |
| RAVEN | No | No |
Data Repositories
DL models can be pre-trained on large datasets (e.g., ImageNet; Millions of records) to establish the parameter settings necessary to identify basic edges, shapes, and lines in an image, then fine-tuned on a specific subset of images. A variety of open-source databases exist for this purpose, and in many cases researchers share annotated data to these databases in a two-way exchange to further support the research community.
LILA BC (Labeled Information Library of Alexandria: Biology and Conservation) is a repository hosted by Microsoft AI for Earth and maintained by a diverse team of computer scientists working on terrestrial and marine biological ML projects. LILA BC directly hosts downloadable labeled imagery and acoustic data, with clear metadata, and points to additional resources as well (e.g., models trained on the referenced data). Most datasets are terrestrial based, but the repository contains 20 million images overall.
Two open-source ML databases specific to marine science are well known. The Monterey Bay Aquarium Research Institute (MBARI) created Fathomnet, a portal designed to accept all marine imagery and video data. Uploaded data can be annotated or not annotated, and a public interface allows other users to annotate data. The stated goal of Fathomnet is to “aggregate >1k fully annotated and localized images per marine species of Animalia (>200k), with the ability to expand and include other underwater concepts (e.g., substrate type, equipment, debris, etc.) for training and validating machine learning models” on a global scale. However, contributions thus far appear to be largely sourced from the western United States.
The University of California San Diego hosts open-source CoralNet with support from NOAA and NSF. CoralNet uses neural networks to automate image annotation specific to coral reefs and benthic imagery that also serves as a repository for labelsets and labeled data. Currently, CoralNet hosts 80.5 million point annotations for 2.1 million benthic images from 2,600 sources around the world.
Example Repositories:
| Name | Information Source | Notes |
| AudioSet | Google AI | 2 million annotated sound clips of human activity from youtube. |
| AWS Open Data Registry | NIST Documentation | Thousands of datasets from different sources and domains. |
| CIFAR-10 | NIST Documentation | Canadian Institute for Advanced Research; Imagery collection for ML models. |
| COCO | NIST Documentation | Large-scale ML dataset; 200,000 labeled images. |
| Data.gov | NIST Documentation | 250,000 open source government datasets. |
| Google AI | NIST Documentation | Periodic data releases specifically for ML research. |
| ImageNet | NIST Documentation | 14 million annotated images. |
| Kaggle | NIST Documentation | Thousands of datasets from different sources and domains. |
| LILA BC | Google AI | Millions of annotated marine/terrestrial biological images, including acoustic datasets and other resources. |
| MNIST | NIST Documentation | 60,000 handwritten digit images. |
| OpenML | NIST Documentation | Open source platform for sharing datasets. |
| Pascal VOC | NIST Documentation | Standardized image datasets, tools, and annotations. |
| UC Irvine ML Repository | NIST Documentation | 600 datasets from the 1980s to current. |
Storage Solutions
Storing large datasets, which are necessary for ML applications, requires careful planning due to costs and availability. The volume and size of image and video data is growing rapidly as technology continues to improve which enables longer data collection periods at higher resolutions. Passive acoustic data alone generates data in terabytes when deployed for continuous, long-term monitoring (Tuia et al. 2022). The increasing availability of remote sensing products from satellite imagery and unmanned aerial vehicles provides additional large datasets in a variety of formats.
Data can be stored locally, but many cloud storage service providers (Microsoft, Amazon, Google, IBM) have integrated their services into their ML pipelines. Storing data in the cloud corresponding with the machine learning pipeline has the benefit of streamlining the data preparation process. For example, Amazon Sagemaker’s Data Wrangler can automatically select data stored in Amazon services such as S3 and Athena, while maintaining the capability to manually query and import files stored elsewhere in generic formats such as CSV files or database tables. The Data Wrangler can then visualize and transform the data to diagnose potential issues before deploying models. Likewise, Google Vertex AI has developed specific pipelines based on BigQuery, which streamlines the use of existing spreadsheets and database tools for ML applications. Google’s Cloud Storage is better suited for image, video, audio, and unstructured data, where it can be stored and pre-processed to optimize the ML pipeline. Amazon, Microsoft, Google, and IBM storage solutions provide benefits for staying within their development ecosystems; however, IBM specifically advertises their capability to deploy on any cloud service.
Languages
ML frameworks prioritize the inclusion of established statistical analytic techniques to simplify and streamline their adoption by data scientists and researchers new to ML. Though these end-to-end solutions and frameworks may not be written in the same languages used for analysis, the ML models themselves can be coded in a variety of languages that are more familiar to data scientists. For example, TensorFlow is written on the back end in C++ and CUDA for optimization, but trained models can be built with Python or Javascript. Flexibility and accessibility is the goal for most of the ML platforms and frameworks which strive to include many options for languages. Python is the most common language across ML frameworks and platforms for model building and training, with several supporting libraries. Alternatively, R is used widely in data science and supported by some end-to-end solutions and frameworks. Amazon Sagemaker, for example, specifically integrates RStudio, which is an enhanced GUI for R that many researchers are accustomed to using for statistical analysis. SPSS and MATLAB are additional statistical tools commonly used in data sciences supported by some ML platforms and frameworks. IBM Watson models can be coded using a high-code solution with Python, lower-code solution with Optimal Programming Language, or no-code by using natural language (i.e., writing in English). Low- and no-code data preparation, analysis, and model building tools are available in the ML platforms which may supersede the need for coding using outside languages for users. The availability of pre-built models provide further no-code solutions for analysis.
Formatting, Model Families, and Use Cases
Formatting
File formats familiar to marine research scientists (csv, json, netCDF, HDF5) can cause performance issues in ML pipelines as file sizes increase because these formats may not be compressed and/or cannot be split for distributed processing. ML frameworks and platforms use modern file formats specifically designed for large datasets, complex models, and distributed processing. Some ML frameworks convert legacy formats to modern formats by offering a Feature Store, but derivative formats may be specific to the framework used. A Feature Store acts as a cache for data that has been processed from a legacy format to a ML format that can be accessed efficiently and repeatedly. The outcome can be a DL model packaged in a single file that contains weights, layers, parameter settings, etc. for a trained model.
| Framework | Accepted Training Formats | Data Sourcing | Model Serving Format |
| Numby/Scikit-Learn | .npy | local | .pkl |
| PyTorch | .csv, .npy, .petastorm, .json, | local, HDFS, S3 | .pt |
| TensorFlow/Keras | .csv, .npy, .tfrecords, .petastorm | local, HDFS, S3 | .pb |
| Pandas/Scikit-Learn | .csv, .npy, .parquet, .h5, .json, .xlsx, .nc, .xml, | local, HDFS, S3 | .pkl |
| PySpark | .csv, .parquet, .orc, .json, .avro, .petastorm | local, HDFS, S3 | .zip |
Table 1. Example of popular ML frameworks with accepted model training formats, where data can be sourced (e.g., Apache Hadoop (HDFS), S3 (Amazon Web Services cloud storage)), and subsequent model serving formats.
Model Types
A wide variety of ML and DL models exist for object detection, classification, and instance segmentation tasks. Traditional ML models include RandomForest, gradient boosting techniques, and other non-parametric models that are familiar to ecologists and marine scientists as established statistical methods, but DL models refer to model families that may be unfamiliar to researchers outside of computer science. We discuss three representative DL model families that marine scientists are likely to encounter, and that are easily accessible in various online tutorials.
Object Detection
YOLO (You Only Look Once; Redmon et al. 2016) is one the first object detection models that combined bounding boxes with classification labels in a single architecture, which simplified the process of object identification and classification into a “single stage”. In other words, the model can “look” at an image once and classify objects in real-time. YOLO models are relatively small, fast, and easy to train. Variations offer nuanced improvements in performance, resolution, and other features (e.g., YOLOv2, YOLOv3, YOLOv4, Scaled-YOLOv4, YOLOv5, PP-YOLO, PP-YOLOv2).
Classification
ResNet models (deep Residual Network; He et al. 2015) are an updated configuration of the CNN architectures initially based on ImageNet in the 2012 competition. CNNs work by breaking images down into a series of layers that individually help quantify edges, lines, and shapes into patterns that are further classified. However, simply increasing the number of layers in a CNN can lead to reduced performance. ResNet models attempt to solve this problem by skipping certain layers to optimize performance. Thus, ResNet models are followed by a number that specifies the number of layers used in the model (i.e., ResNet34).
Instance Segmentation
Mask RCNN models ( Region-based Convolutional Network; He et al. 2017) extend the CNN architecture to allow polygons around an object of interest by classifying individual pixels in an image (e.g., the outline of a face versus a rectangular bounding box). Developed by Facebook AI, this model utilizes masks, in addition to bounding boxes that identify objects and classification labels, that determine if a pixel is a part of an object.
Data Standards
Progress towards standards
Metadata, and other data standards for artificial intelligence datasets are in development. The Earth Science Information Partners (ESIP) Data Readiness Cluster produced a draft AI Ready Data Checklist in 2022 that is easy to follow and provides an intuitive means for recording AI relevant metadata (Appendix D). Additionally, AI/ML conferences regularly produce AI checklists for all code, data, and model submissions that are intuitive as well. Until more formal standards are adopted, maintaining simple checklists continues to be a best practice.
Following sector specific dataset repositories and peer-reviewed literature for updates and examples is also an efficient strategy for understanding metadata guidelines, in addition to other solutions specific to AI applications in marine science. Castro et al. (2016) summarized some of these guidelines across four broad and interrelated concerns that AI metadata should capture:
- Provenance: Where did the training data, AI model, software, and hardware originate, and what transformations have the data undergone before the findings were reported?
- Reproducibility: Can an independent party replicate the precise AI workflow and reported results, using the same data and algorithms?
- Replicability: Can an independent party run similar (but not identical) ML analyses on similar (but not necessarily the same) data and come to the same conclusions?
- Reusability: How easily can the trained AI models be applied to new data or other new situations?
Formal AI standards are forthcoming and some standards are published. The International Organization for Standardization (ISO) lists published standards for AI data on topics related to trustworthiness, biases, governance, and risk, while additional AI standards are under development. The American National Standards’ (ANSI) webstore has nine pages of AI standards, but most are written in mandarin. Otherwise, within the United States, the National Institute of Standards and Technology (NIST) within the Department of Commerce is the Federal AT standards coordinating agency. Currently, NIST is in the process of developing metadata standards for formatting, training, validation, and testing AI pipelines. NIST’s development process is outlined in a 2019 report titled “A Plan for Federal Engagement in Developing Technical Standards and Related Tools”, which also references ISO and ANSI standards. Additionally, NOAA intends to publish a document for AI standards that are consistent with the NOAA AI Strategic Plan.